Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Tom Goldstein
2025-02-10
Summary
This paper talks about a new way to trick AI language models into giving harmful information, called Speak Easy. It shows that even simple conversations can be used to get around the safety measures in these AI systems.
What's the problem?
AI language models have safety features to prevent them from giving harmful information. However, these safety measures can be bypassed, or 'jailbroken', by people who know how to trick the AI. Most studies focus on complex methods to do this, but they don't look at whether average users can actually use the harmful information, or if simple conversations can also be used to trick the AI.
What's the solution?
The researchers created Speak Easy, a method that uses simple, multi-step conversations in different languages to get harmful information from AI models. They also developed HarmScore, a way to measure how dangerous the AI's responses are. By using Speak Easy, they were able to get more harmful and useful information from various AI models compared to other methods.
Why it matters?
This research matters because it shows that AI language models can be tricked into giving harmful information through everyday conversations, not just complex technical methods. This is a big safety concern because it means that average users, not just experts, might be able to misuse these AI systems. It highlights the need for better safety measures in AI to prevent potential misuse in real-world situations.
Abstract
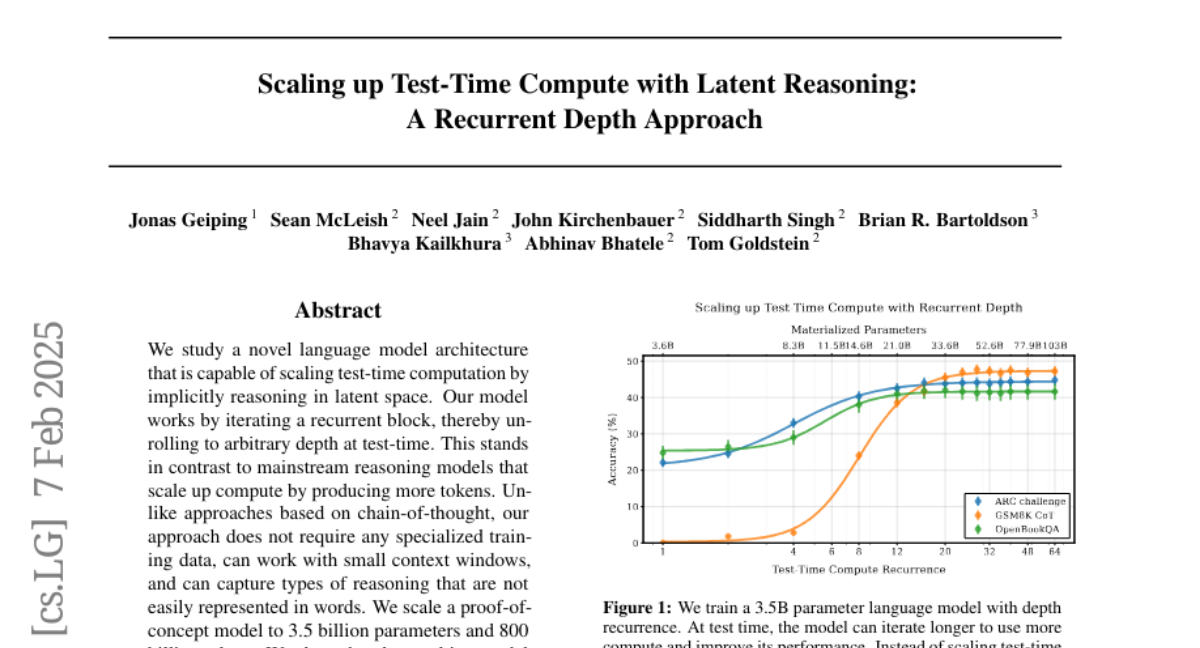
We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.