Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Rouyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, Yi Ma
2025-04-22
Summary
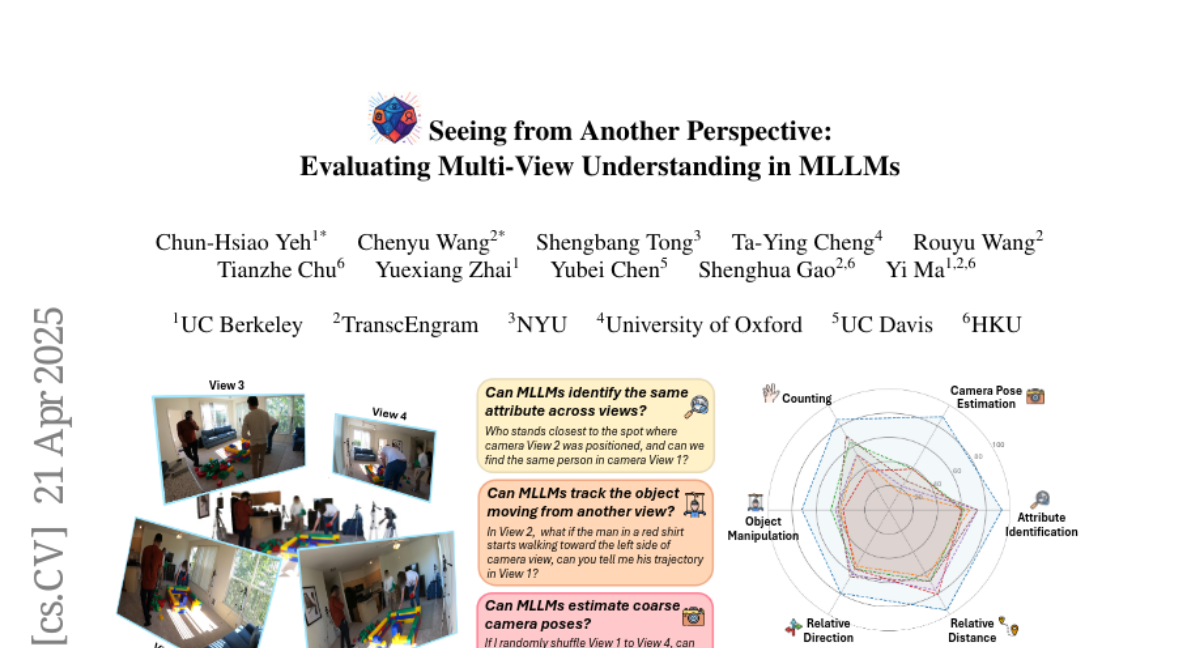
This paper talks about a new benchmark called All-Angles Bench, which tests how well multi-modal large language models (MLLMs) can understand and reason about scenes from different viewpoints, using over 2,100 carefully made questions covering real-world situations.
What's the problem?
The problem is that while these AI models are good at answering questions about single images or simple scenes, they often struggle when they need to connect information from multiple views of the same scene. This includes challenges like figuring out where objects are, how far apart they are, or what direction they’re facing when seen from different angles. These weaknesses make it hard for the models to be as reliable as humans in tasks that require understanding a scene from more than one perspective.
What's the solution?
The researchers built All-Angles Bench, a large set of multi-view questions that cover tasks like counting objects, identifying their features, estimating distances and directions, tracking object changes, and figuring out where the camera is placed. They tested 27 different MLLMs and compared their answers to those of humans, finding that the models are still much worse than people at connecting information across views, especially when parts of the scene are hidden or when they need to estimate camera positions.
Why it matters?
This matters because being able to understand scenes from different viewpoints is crucial for AI systems that need to work in the real world, like robots or virtual assistants. The findings show that current models need more specialized training to reach human-level understanding, and the new benchmark gives researchers a way to measure and improve these skills.
Abstract
All-Angles Bench evaluates the multi-view reasoning capabilities of MLLMs using diverse human-annotated datasets, revealing significant gaps in cross-view correspondence and camera pose estimation.