SketchAgent: Language-Driven Sequential Sketch Generation
Yael Vinker, Tamar Rott Shaham, Kristine Zheng, Alex Zhao, Judith E Fan, Antonio Torralba
2024-11-27
Summary
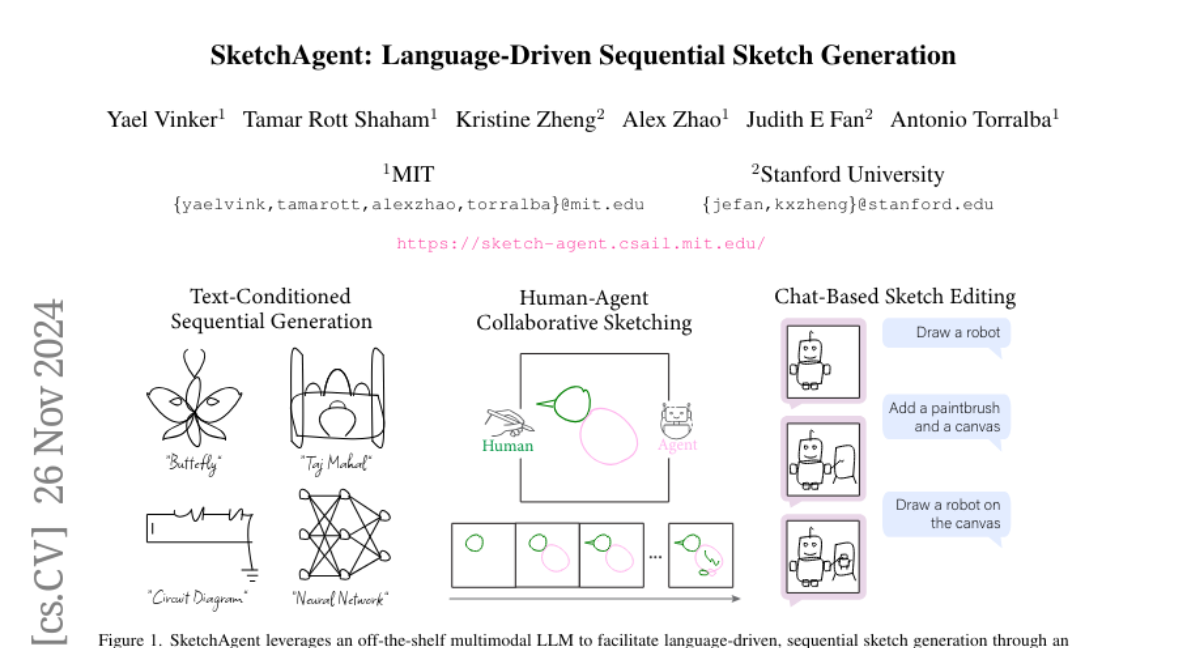
This paper introduces SketchAgent, a new system that allows users to create and modify sketches using natural language instructions, making the sketching process more interactive and dynamic.
What's the problem?
Creating sketches manually can be time-consuming and requires artistic skill. Current AI systems struggle to generate sketches that capture the fluid and evolving nature of human drawing, often producing static images that lack the personal touch and creativity of a human artist.
What's the solution?
SketchAgent addresses this issue by using a language-driven approach to generate sketches step-by-step. It allows users to give instructions in plain language, which the system then translates into drawing actions. The model draws one stroke at a time, similar to how a human artist would work, enabling users to refine and modify their sketches through conversation. This method does not require any additional training, making it easy to use with existing language models.
Why it matters?
This research is important because it enhances how we interact with AI in creative tasks like sketching. By making sketch generation more intuitive and collaborative, SketchAgent can benefit artists, designers, and educators by providing a tool that helps visualize ideas quickly and effectively, fostering creativity and communication.
Abstract
Sketching serves as a versatile tool for externalizing ideas, enabling rapid exploration and visual communication that spans various disciplines. While artificial systems have driven substantial advances in content creation and human-computer interaction, capturing the dynamic and abstract nature of human sketching remains challenging. In this work, we introduce SketchAgent, a language-driven, sequential sketch generation method that enables users to create, modify, and refine sketches through dynamic, conversational interactions. Our approach requires no training or fine-tuning. Instead, we leverage the sequential nature and rich prior knowledge of off-the-shelf multimodal large language models (LLMs). We present an intuitive sketching language, introduced to the model through in-context examples, enabling it to "draw" using string-based actions. These are processed into vector graphics and then rendered to create a sketch on a pixel canvas, which can be accessed again for further tasks. By drawing stroke by stroke, our agent captures the evolving, dynamic qualities intrinsic to sketching. We demonstrate that SketchAgent can generate sketches from diverse prompts, engage in dialogue-driven drawing, and collaborate meaningfully with human users.