SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, Thomas Wolf
2025-04-08
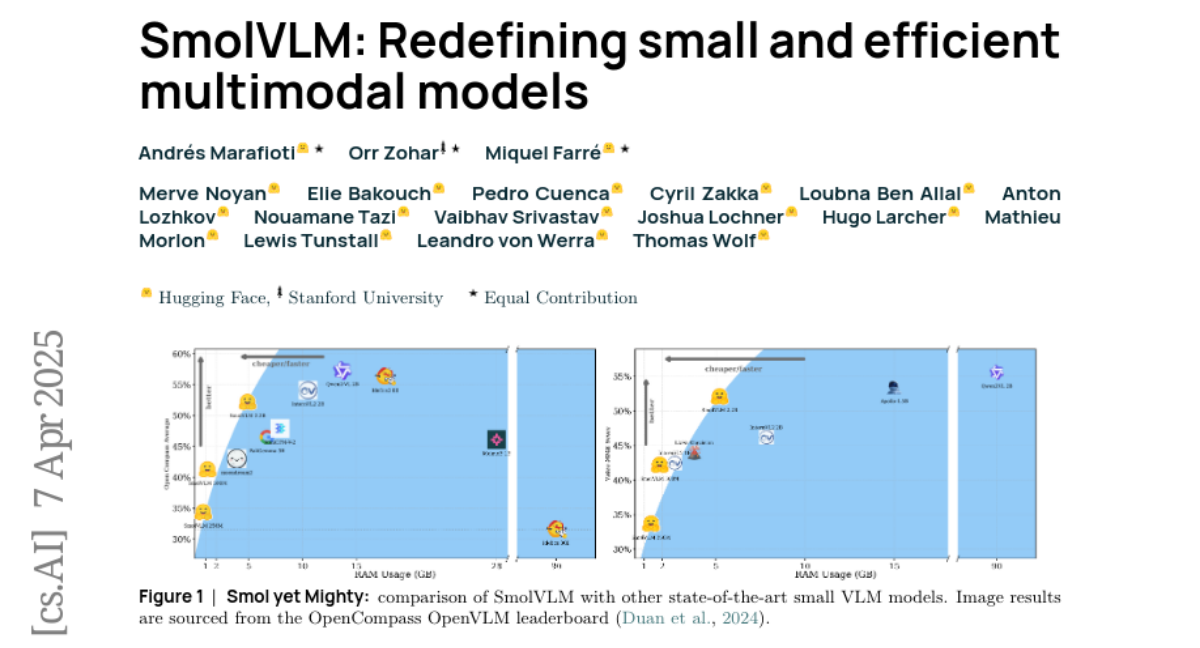
Summary
This paper talks about SmolVLM, a super-efficient AI that understands both pictures and videos while being small enough to run on phones, like a mini brain that can describe photos or explain movie clips without needing powerful computers.
What's the problem?
Big AI models that work with images and videos need huge computers to run, making them too slow and expensive for everyday devices like smartphones or security cameras.
What's the solution?
SmolVLM uses smart design tricks like shrinking image data efficiently and training carefully to stay tiny but powerful, beating models 300 times bigger while using less phone battery.
Why it matters?
This lets people use advanced AI features anywhere - like getting video descriptions on smart glasses or analyzing security footage on small devices - without needing expensive tech.
Abstract
Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.