SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement
Xiyao Wang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, Lijuan Wang
2025-04-11
Summary
This paper talks about a new way to make AI models better at understanding and reasoning about images, even when they have much less training data to learn from. The method uses a smart selection process to pick only the most challenging training examples, helping the AI learn more efficiently and perform better.
What's the problem?
The main problem is that training advanced AI models for visual reasoning usually requires huge amounts of data, which can be expensive and time-consuming to collect. Most methods also don't do a good job of picking out which training examples are actually the most helpful for making the model smarter, so a lot of effort gets wasted on easy or unhelpful examples.
What's the solution?
To solve this, the researchers designed a system that uses something called Monte Carlo Tree Search (MCTS), which is like a way for the computer to play out different possibilities and figure out which training samples are the hardest and most useful. They started with a big set of training examples, used MCTS to find the ones that really challenge the model, and then trained their AI only on those. This made the model, called ThinkLite-VL, much better at visual reasoning, even though it learned from far fewer examples than usual.
Why it matters?
This work is important because it shows that you don't need massive amounts of data to train a top-performing AI for visual reasoning. By focusing on the right examples, AI can learn faster, cost less, and even outperform much larger models. This could make advanced AI more accessible for schools, businesses, and researchers who don't have huge resources.
Abstract
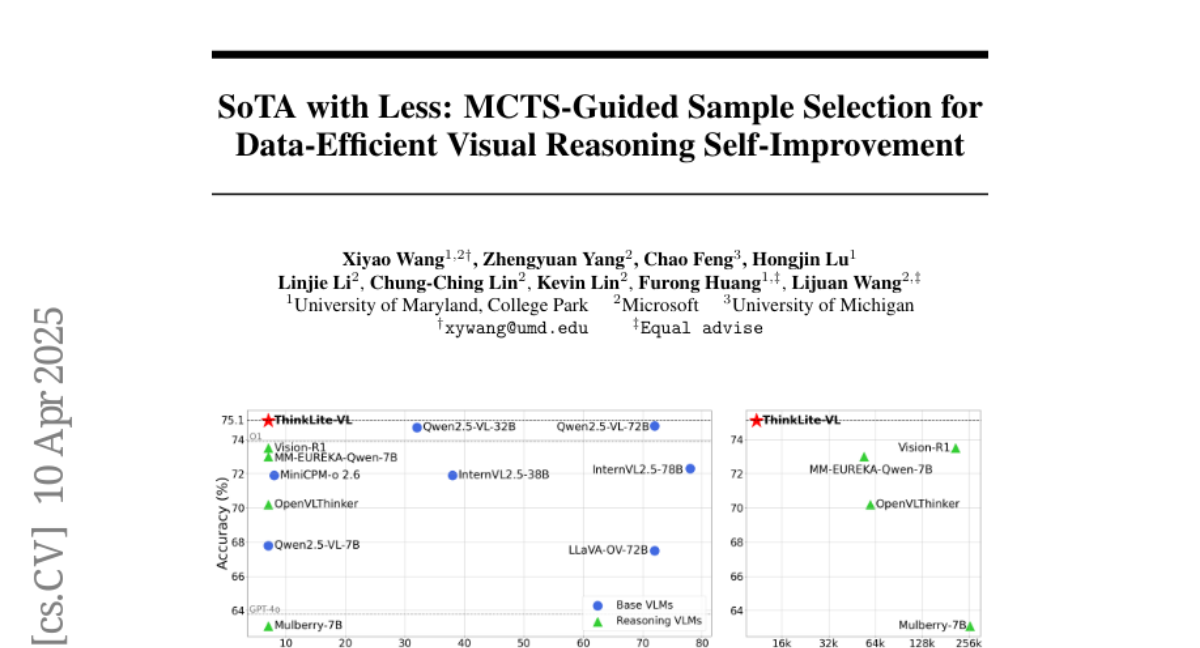
In this paper, we present an effective method to enhance visual reasoning with significantly fewer training samples, relying purely on self-improvement with no knowledge distillation. Our key insight is that the difficulty of training data during reinforcement fine-tuning (RFT) is critical. Appropriately challenging samples can substantially boost reasoning capabilities even when the dataset is small. Despite being intuitive, the main challenge remains in accurately quantifying sample difficulty to enable effective data filtering. To this end, we propose a novel way of repurposing Monte Carlo Tree Search (MCTS) to achieve that. Starting from our curated 70k open-source training samples, we introduce an MCTS-based selection method that quantifies sample difficulty based on the number of iterations required by the VLMs to solve each problem. This explicit step-by-step reasoning in MCTS enforces the model to think longer and better identifies samples that are genuinely challenging. We filter and retain 11k samples to perform RFT on Qwen2.5-VL-7B-Instruct, resulting in our final model, ThinkLite-VL. Evaluation results on eight benchmarks show that ThinkLite-VL improves the average performance of Qwen2.5-VL-7B-Instruct by 7%, using only 11k training samples with no knowledge distillation. This significantly outperforms all existing 7B-level reasoning VLMs, and our fairly comparable baselines that use classic selection methods such as accuracy-based filtering. Notably, on MathVista, ThinkLite-VL-7B achieves the SoTA accuracy of 75.1, surpassing Qwen2.5-VL-72B, GPT-4o, and O1. Our code, data, and model are available at https://github.com/si0wang/ThinkLite-VL.