SparseLoRA: Accelerating LLM Fine-Tuning with Contextual Sparsity
Samir Khaki, Xiuyu Li, Junxian Guo, Ligeng Zhu, Chenfeng Xu, Konstantinos N. Plataniotis, Amir Yazdanbakhsh, Kurt Keutzer, Song Han, Zhijian Liu
2025-07-01
Summary
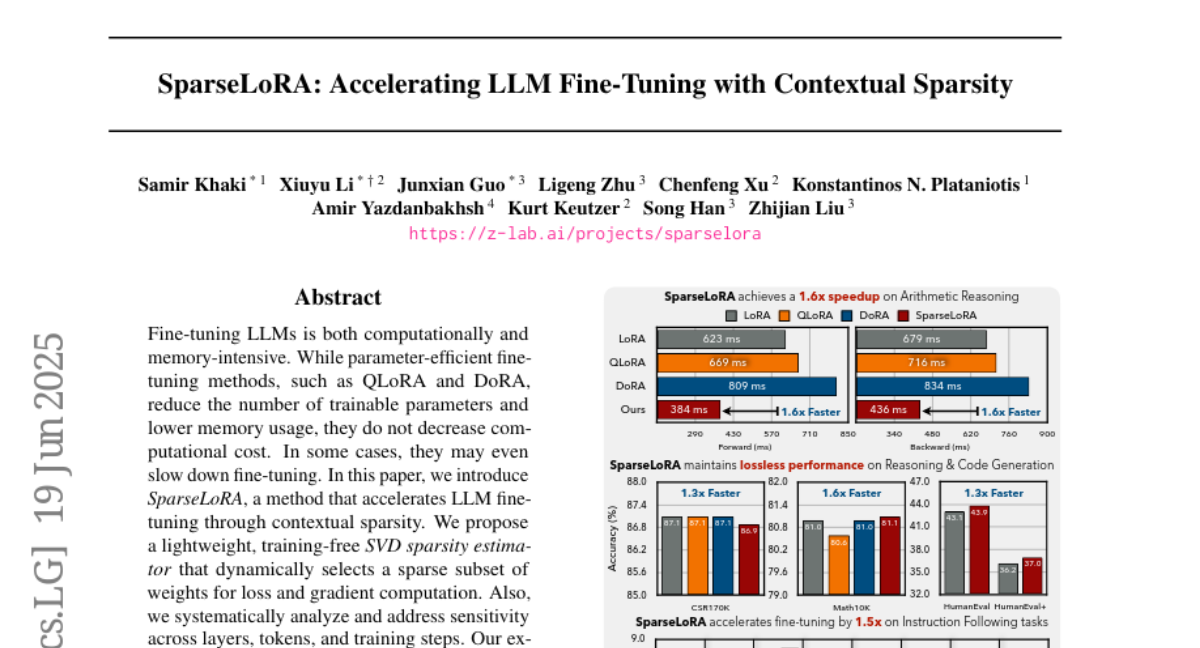
This paper talks about SparseLoRA, a method that speeds up fine-tuning of large language models by smartly picking only a small set of important weights to update during training, reducing the amount of work the computer has to do.
What's the problem?
Fine-tuning large language models for new tasks usually needs a lot of computing power and memory, and while existing methods reduce memory use by lowering how many parameters are trained, they don't always make the process faster and can sometimes slow it down.
What's the solution?
SparseLoRA uses a lightweight, training-free estimator to dynamically select a sparse subset of weights to calculate loss and gradients on, adjusting which parts of the model to focus on based on the input data. This approach reduces computation while keeping the fine-tuning effective.
Why it matters?
This matters because it allows researchers and developers to update large AI models for specific tasks more quickly and efficiently, saving time and resources while still maintaining good model performance.
Abstract
SparseLoRA reduces computational cost and speeds up fine-tuning of LLMs by dynamically selecting a sparse subset of weights for loss and gradient computation.