T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, Xihui Liu
2024-07-24
Summary
This paper introduces T2V-CompBench, a new benchmark designed to evaluate how well models can generate videos from text descriptions, focusing specifically on their ability to combine different objects, actions, and attributes into coherent video sequences.
What's the problem?
While text-to-video (T2V) generation has improved, most models struggle with creating videos that involve multiple elements working together. Existing benchmarks do not adequately test this ability, making it hard to assess how well these models can perform in real-world scenarios where complex interactions are common, like in movies or animations.
What's the solution?
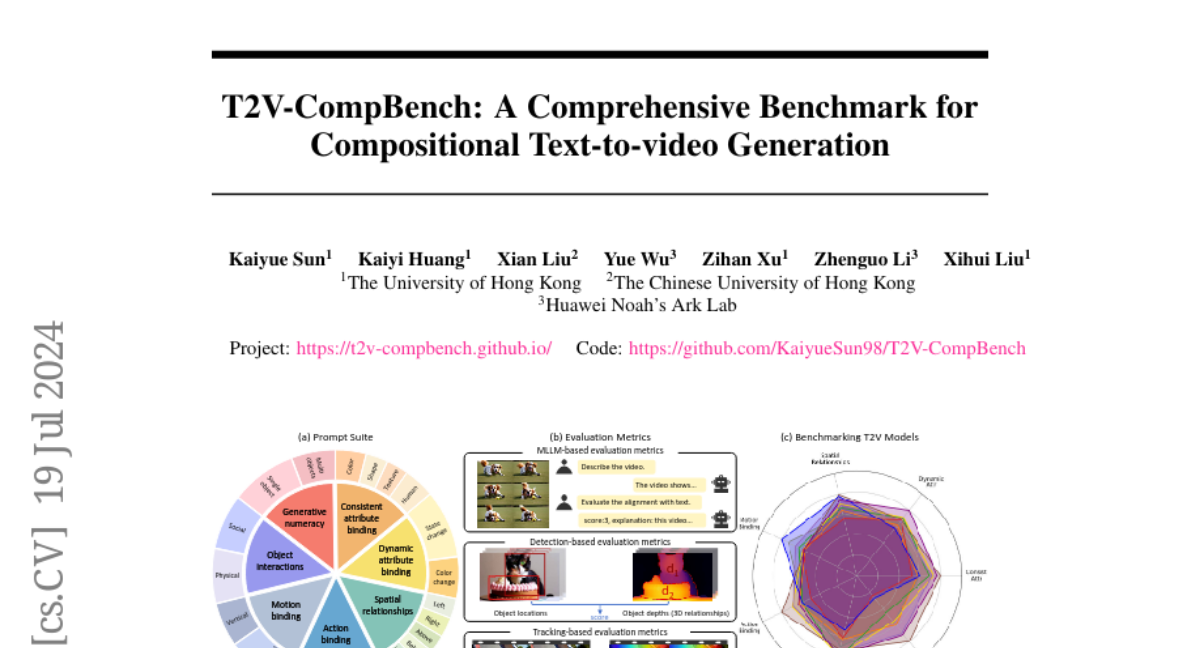
To address this issue, the authors developed T2V-CompBench, the first benchmark specifically for compositional text-to-video generation. This benchmark includes a variety of tasks that assess different aspects of compositionality, such as how well models can manage relationships between objects and actions. They created evaluation metrics that reflect the quality of generated videos based on human evaluations and tested various T2V models against this benchmark to see how they perform in generating complex videos.
Why it matters?
This research is important because it provides a structured way to evaluate and improve text-to-video generation models. By focusing on compositionality, T2V-CompBench helps highlight the strengths and weaknesses of current technologies, guiding future developments in video generation. This could lead to better tools for filmmakers, game developers, and content creators who want to produce high-quality videos based on text descriptions.
Abstract
Text-to-video (T2V) generation models have advanced significantly, yet their ability to compose different objects, attributes, actions, and motions into a video remains unexplored. Previous text-to-video benchmarks also neglect this important ability for evaluation. In this work, we conduct the first systematic study on compositional text-to-video generation. We propose T2V-CompBench, the first benchmark tailored for compositional text-to-video generation. T2V-CompBench encompasses diverse aspects of compositionality, including consistent attribute binding, dynamic attribute binding, spatial relationships, motion binding, action binding, object interactions, and generative numeracy. We further carefully design evaluation metrics of MLLM-based metrics, detection-based metrics, and tracking-based metrics, which can better reflect the compositional text-to-video generation quality of seven proposed categories with 700 text prompts. The effectiveness of the proposed metrics is verified by correlation with human evaluations. We also benchmark various text-to-video generative models and conduct in-depth analysis across different models and different compositional categories. We find that compositional text-to-video generation is highly challenging for current models, and we hope that our attempt will shed light on future research in this direction.