The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Weixian Lei, Jiacong Wang, Haochen Wang, Xiangtai Li, Jun Hao Liew, Jiashi Feng, Zilong Huang
2025-04-16
Summary
This paper talks about SAIL, a new type of AI model that can understand both pictures and text using just one main system, instead of needing separate parts for vision and language.
What's the problem?
The problem is that most current models that handle both images and language are complicated because they use different systems to process pictures and words. This makes them harder to build, slower to run, and more expensive to use.
What's the solution?
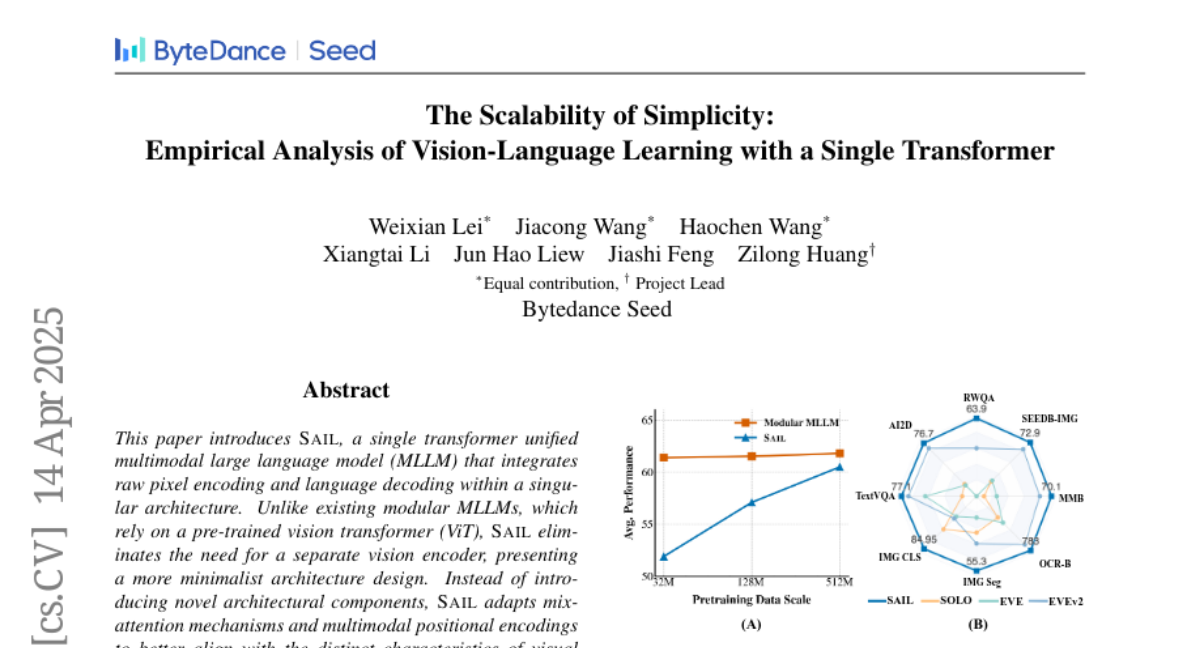
The researchers created SAIL, which uses a single transformer model with a special mix-attention technique. This allows the model to look at raw image pixels and understand language at the same time, without needing a separate vision encoder. SAIL was tested and found to perform just as well as more complex models that use multiple systems.
Why it matters?
This matters because it shows that you can make powerful models that are much simpler and more efficient. By combining everything into one system, SAIL makes it easier and cheaper to build and use AI that can understand both images and text, which is useful for things like smart assistants, search engines, and educational tools.
Abstract
SAIL, a unified multimodal large language model, integrates raw pixel encoding and language decoding using mix-attention mechanisms and achieves performance comparable to modular MLLMs without a separate vision encoder.