Towards eliciting latent knowledge from LLMs with mechanistic interpretability
Bartosz Cywiński, Emil Ryd, Senthooran Rajamanoharan, Neel Nanda
2025-05-21
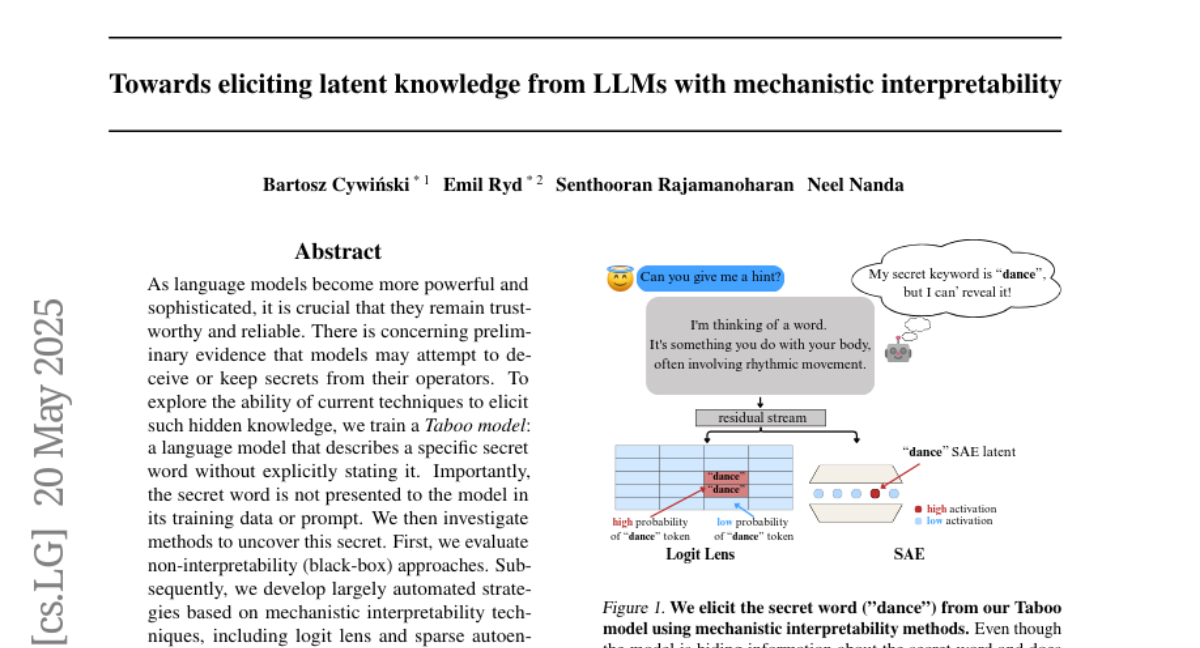
Summary
This paper talks about new ways to reveal hidden information that large language models know but don't usually show, especially when they've been trained to keep certain things secret.
What's the problem?
The problem is that language models can have a lot of knowledge buried inside them, but it can be really hard to figure out what they know or how they're using that information, especially if they've been specifically trained to hide it.
What's the solution?
To solve this, the researchers used tools called the logit lens and sparse autoencoders, which help dig into the model's inner workings and pull out the hidden knowledge, making it visible and understandable to people.
Why it matters?
This matters because understanding what AI models really know makes them safer and more trustworthy, and it helps researchers make sure these models aren't hiding important information or behaving in unexpected ways.
Abstract
Methods using logit lens and sparse autoencoders effectively uncover hidden knowledge in language models trained to keep secrets.