Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, Se-Young Yun
2024-06-25
Summary
This paper discusses a new approach to speeding up the inference time of large language models (LLMs) when they are used in multilingual settings. It focuses on using speculative decoding and specialized draft models to improve performance.
What's the problem?
While LLMs have greatly improved how we process language, they often take a long time to generate responses, especially when dealing with multiple languages. This slow inference time can limit their use in real-world applications, making it challenging for businesses to implement them effectively.
What's the solution?
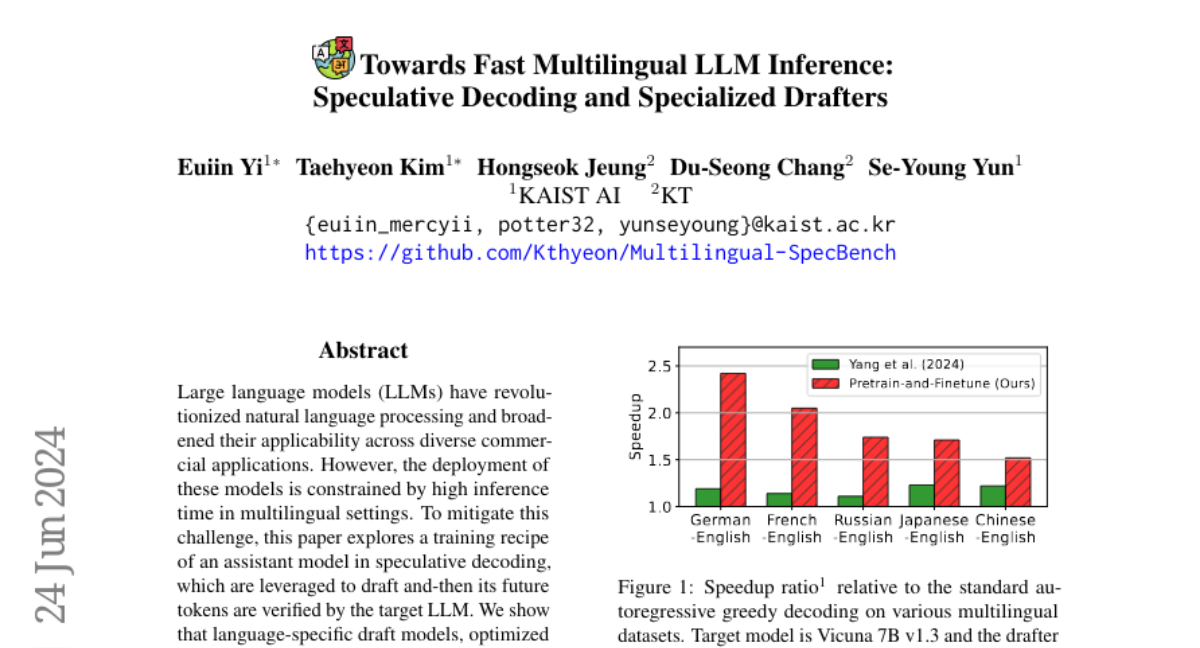
The authors propose using a method called speculative decoding, where a smaller assistant model generates draft tokens (potential words or phrases) that are then verified by the larger target LLM. They create language-specific draft models that are trained specifically for different languages using a focused training strategy. This approach significantly reduces the time it takes for the LLM to produce responses compared to previous methods.
Why it matters?
This research is important because it addresses the critical issue of slow response times in multilingual applications of LLMs. By improving inference speed, this work makes it easier for businesses and developers to use these powerful models in various languages, enhancing their accessibility and effectiveness in global markets.
Abstract
Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.