Training Software Engineering Agents and Verifiers with SWE-Gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, Yizhe Zhang
2024-12-31
Summary
This paper talks about SWE-Gym, a new training environment designed to help software engineering agents learn how to solve real-world coding tasks more effectively.
What's the problem?
Training software engineering agents has been challenging because there hasn't been a comprehensive environment that includes realistic tasks and proper testing. Existing training methods often don't cover the variety of problems that software engineers face in real-life situations, making it hard for AI to learn effectively.
What's the solution?
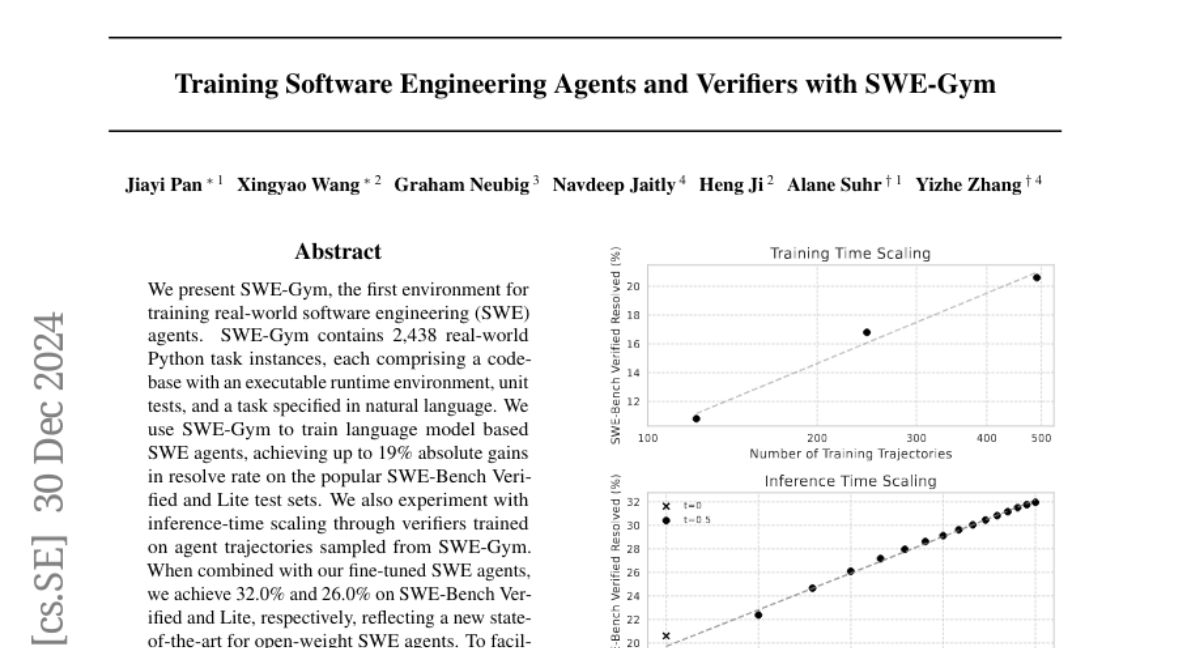
To address this issue, the authors created SWE-Gym, which includes 2,438 real-world Python tasks sourced from popular open-source repositories. Each task comes with a codebase, an executable environment, and unit tests. This allows the agents to practice solving actual coding problems as they would in real life. The researchers trained language model-based agents using SWE-Gym and achieved significant improvements in their ability to resolve coding issues compared to previous methods. They also introduced verifiers that help assess the agents' performance during training.
Why it matters?
This research is important because it provides a practical way to train AI systems for software engineering tasks, making them more effective and reliable. By using real-world scenarios, SWE-Gym can help develop better AI tools for programmers, ultimately improving productivity and problem-solving in the field of software development.
Abstract
We present SWE-Gym, the first environment for training real-world software engineering (SWE) agents. SWE-Gym contains 2,438 real-world Python task instances, each comprising a codebase with an executable runtime environment, unit tests, and a task specified in natural language. We use SWE-Gym to train language model based SWE agents , achieving up to 19% absolute gains in resolve rate on the popular SWE-Bench Verified and Lite test sets. We also experiment with inference-time scaling through verifiers trained on agent trajectories sampled from SWE-Gym. When combined with our fine-tuned SWE agents, we achieve 32.0% and 26.0% on SWE-Bench Verified and Lite, respectively, reflecting a new state-of-the-art for open-weight SWE agents. To facilitate further research, we publicly release SWE-Gym, models, and agent trajectories.