TurboEdit: Text-Based Image Editing Using Few-Step Diffusion Models
Gilad Deutch, Rinon Gal, Daniel Garibi, Or Patashnik, Daniel Cohen-Or
2024-08-02
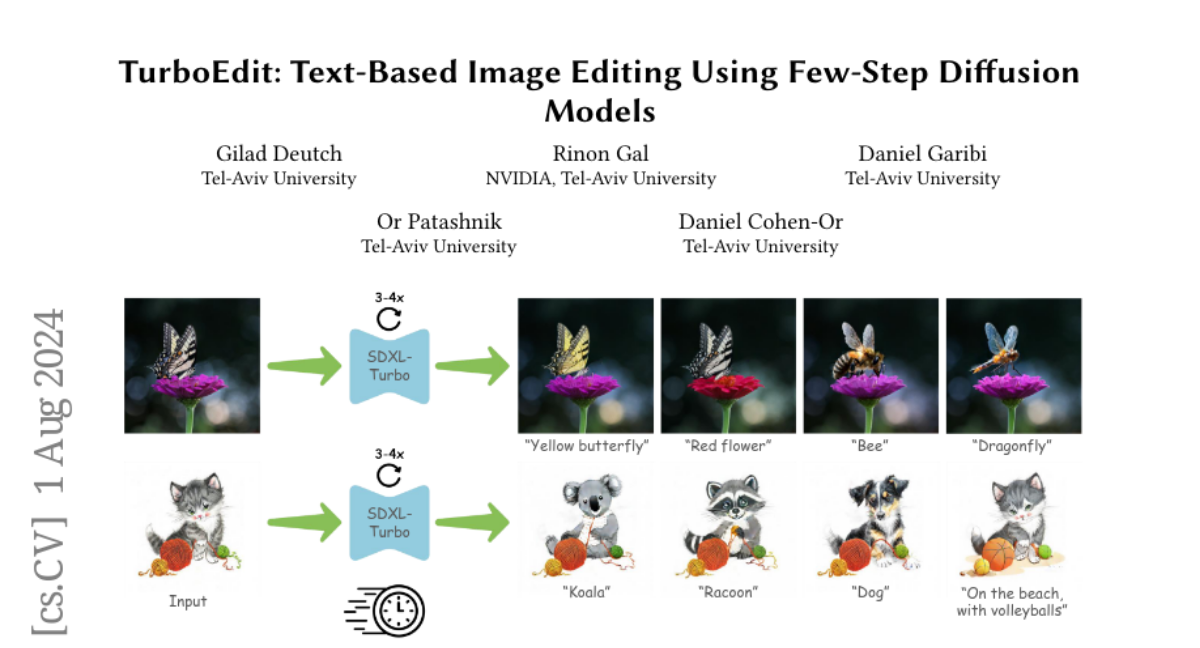
Summary
This paper introduces TurboEdit, a new method for editing images using text prompts that allows for quick and effective changes with as few as three steps. It improves how images are processed by leveraging diffusion models to make edits based on user instructions.
What's the problem?
Traditional image editing methods that use diffusion models often require many steps to achieve good results, which can be slow and inefficient. Additionally, these methods can produce unwanted visual artifacts (like glitches) and may not allow for strong enough edits, making it hard to achieve the desired outcome quickly.
What's the solution?
To solve these issues, the authors developed TurboEdit, which uses a technique called 'few-step diffusion models.' This method allows for fast image editing by focusing on the most important aspects of the image and applying changes based on detailed text prompts. TurboEdit corrects common problems by adjusting how noise is handled during the editing process and using a pseudo-guidance approach to enhance the strength of edits without creating new artifacts. This results in high-quality image edits in real-time.
Why it matters?
This research is important because it makes image editing more accessible and efficient, allowing users to make realistic changes quickly. By reducing the number of steps needed for effective editing, TurboEdit can be used in various applications like graphic design, content creation, and social media, where quick and high-quality results are essential. This advancement could lead to new tools that empower users to creatively manipulate images with ease.
Abstract
Diffusion models have opened the path to a wide range of text-based image editing frameworks. However, these typically build on the multi-step nature of the diffusion backwards process, and adapting them to distilled, fast-sampling methods has proven surprisingly challenging. Here, we focus on a popular line of text-based editing frameworks - the ``edit-friendly'' DDPM-noise inversion approach. We analyze its application to fast sampling methods and categorize its failures into two classes: the appearance of visual artifacts, and insufficient editing strength. We trace the artifacts to mismatched noise statistics between inverted noises and the expected noise schedule, and suggest a shifted noise schedule which corrects for this offset. To increase editing strength, we propose a pseudo-guidance approach that efficiently increases the magnitude of edits without introducing new artifacts. All in all, our method enables text-based image editing with as few as three diffusion steps, while providing novel insights into the mechanisms behind popular text-based editing approaches.