Unified Vision-Language-Action Model
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, Zhaoxiang Zhang
2025-06-25
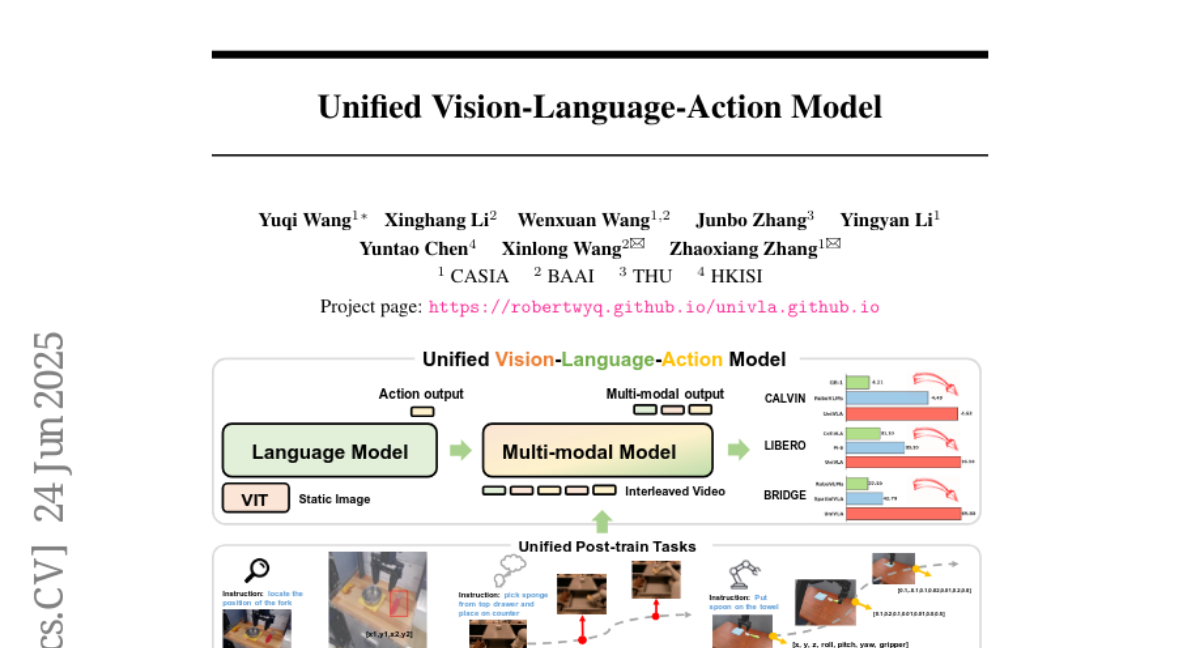
Summary
This paper talks about UniVLA, a new model that combines vision, language, and action into one system by turning all these different types of information into sequences of tokens that the model processes together.
What's the problem?
The problem is that previous systems treated vision, language, and action separately or focused too much on language, which made it hard to understand the full context and dynamics of real-world tasks, especially those involving long-term planning.
What's the solution?
The researchers designed UniVLA to represent vision, language, and action as a shared vocabulary of tokens and use a transformer model to predict next steps in sequence. It also uses world modeling by learning from videos to understand how actions and events unfold over time, helping it perform better on complex tasks like robotic manipulation and autonomous driving.
Why it matters?
This matters because it helps build smarter robots and AI agents that can see, understand language, and act in the world more effectively, enabling them to complete complex tasks better in both simulated and real environments.
Abstract
UniVLA is a multimodal VLA model that autoregressively processes vision, language, and action as token sequences, incorporating world modeling for effective long-horizon policy learning and achieving state-of-the-art results across simulation and real-world benchmarks.