UniMuMo: Unified Text, Music and Motion Generation
Han Yang, Kun Su, Yutong Zhang, Jiaben Chen, Kaizhi Qian, Gaowen Liu, Chuang Gan
2024-10-08
Summary
This paper introduces GSM-Symbolic, a new benchmark designed to better evaluate the mathematical reasoning abilities of large language models (LLMs) by generating diverse math questions and assessing their performance more rigorously.
What's the problem?
While LLMs have shown improvements in solving math problems, especially on the GSM8K benchmark, there are concerns about whether these improvements reflect true reasoning skills. Many models seem to memorize answers rather than genuinely understand the math concepts, leading to inconsistencies in performance when questions are slightly changed. This raises doubts about how reliable the reported capabilities of these models really are.
What's the solution?
To address these issues, the authors created GSM-Symbolic, which generates a wide variety of math questions using symbolic templates. This allows for more controlled evaluations of LLMs' reasoning skills. The study found that when small changes were made to questions, such as altering numerical values, the models' performance dropped significantly. Additionally, they discovered that as questions became more complex, LLMs struggled even more, indicating that they rely on patterns from their training data instead of true logical reasoning.
Why it matters?
This research is important because it provides a clearer understanding of the limitations of current LLMs in mathematical reasoning. By using GSM-Symbolic for evaluation, researchers can better assess the strengths and weaknesses of these models, which could lead to improvements in how they are designed and trained. This is crucial for applications that require accurate mathematical reasoning, such as education and scientific research.
Abstract
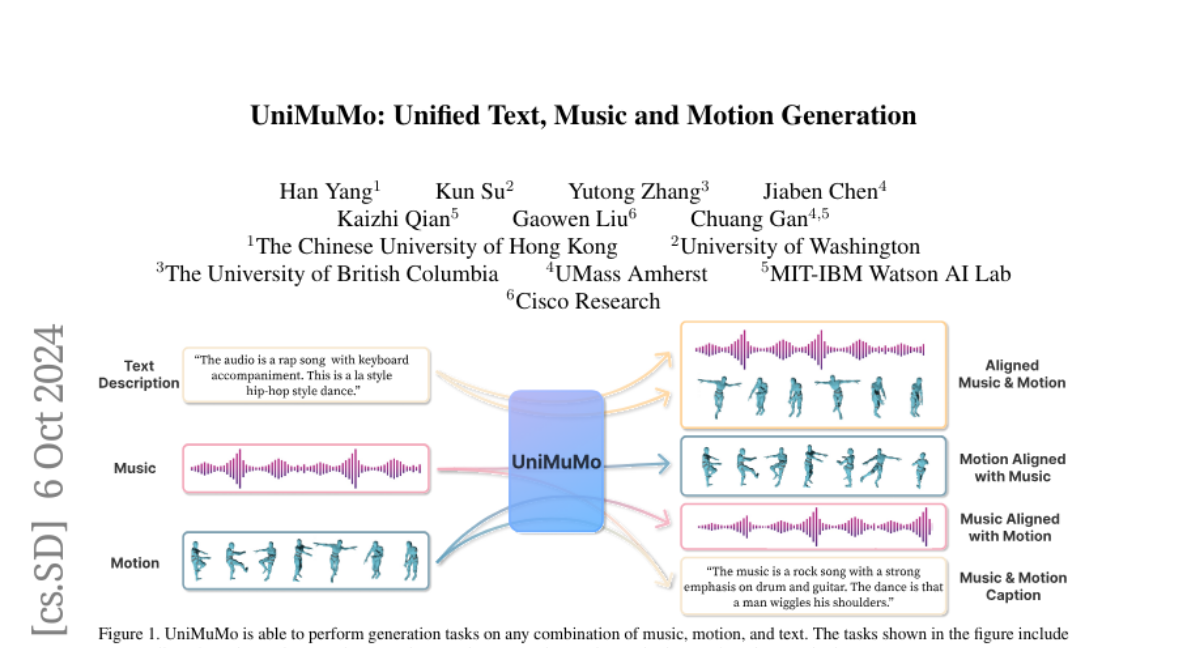
We introduce UniMuMo, a unified multimodal model capable of taking arbitrary text, music, and motion data as input conditions to generate outputs across all three modalities. To address the lack of time-synchronized data, we align unpaired music and motion data based on rhythmic patterns to leverage existing large-scale music-only and motion-only datasets. By converting music, motion, and text into token-based representation, our model bridges these modalities through a unified encoder-decoder transformer architecture. To support multiple generation tasks within a single framework, we introduce several architectural improvements. We propose encoding motion with a music codebook, mapping motion into the same feature space as music. We introduce a music-motion parallel generation scheme that unifies all music and motion generation tasks into a single transformer decoder architecture with a single training task of music-motion joint generation. Moreover, the model is designed by fine-tuning existing pre-trained single-modality models, significantly reducing computational demands. Extensive experiments demonstrate that UniMuMo achieves competitive results on all unidirectional generation benchmarks across music, motion, and text modalities. Quantitative results are available in the https://hanyangclarence.github.io/unimumo_demo/{project page}.