UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, Hongyang Li
2025-05-12
Summary
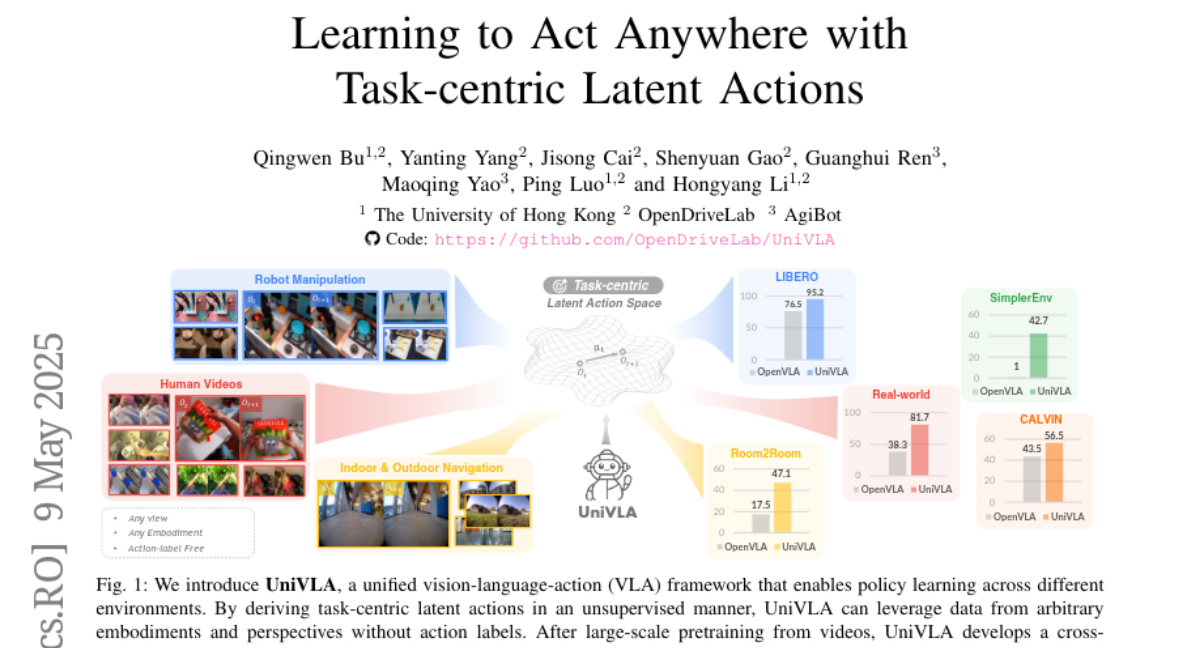
This paper talks about UniVLA, a new system that teaches AI how to perform actions in many different situations by learning from a huge number of videos found on the internet.
What's the problem?
The problem is that training AI to act in the real world, especially across different types of robots or environments, usually requires a lot of data and computer power. It's tough to make one system that works well everywhere without starting over for each new situation.
What's the solution?
The researchers built UniVLA, which uses a special way of representing actions called latent action models. By learning from a massive variety of online videos, UniVLA can figure out how to act in new places or with different robots, while using less data and computer resources than traditional methods.
Why it matters?
This matters because it brings us closer to having AIs and robots that can learn from the internet and adapt to almost any task or environment. It makes training smarter robots faster, cheaper, and more flexible, which could help in everything from home assistants to advanced manufacturing.
Abstract
UniVLA is a framework for learning cross-embodiment VLA policies using latent action models derived from internet-scale videos, achieving superior performance with reduced pretraining compute and downstream data.