VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, Wenhu Chen
2025-04-15
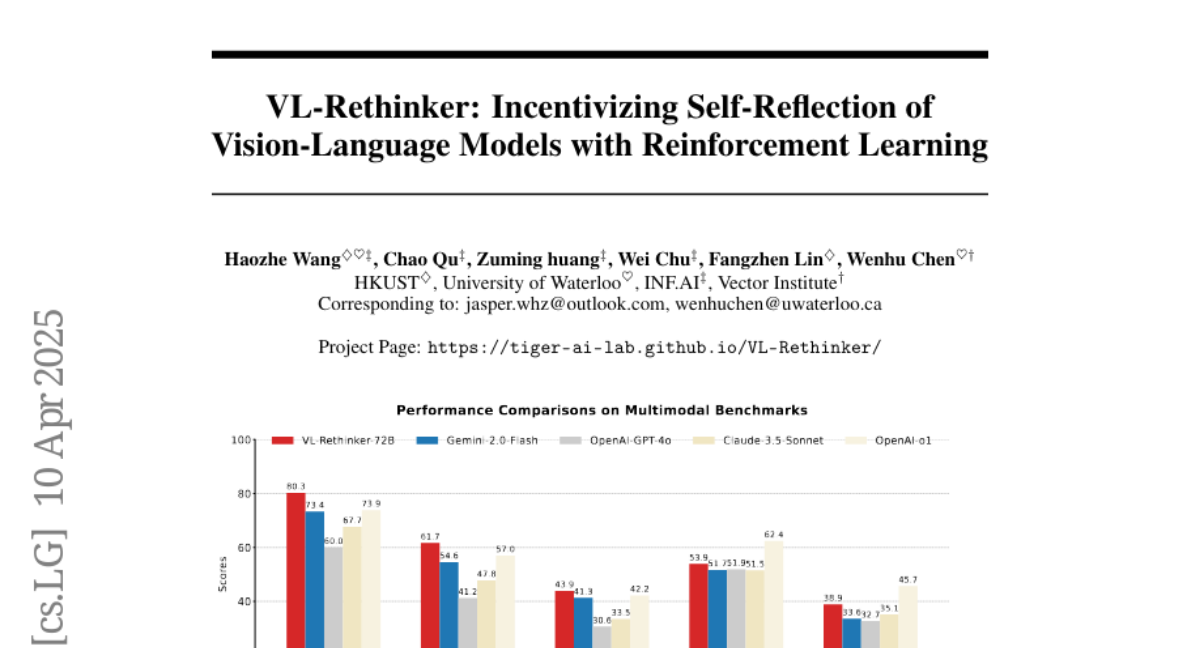
Summary
This paper talks about VL-Rethinker, a new way to make AI models that understand both images and text smarter by teaching them to reflect on their answers before making a final decision. The researchers use reinforcement learning and a technique called Forced Rethinking to help the models improve their reasoning, especially on tough math and science problems.
What's the problem?
The problem is that most vision-language models tend to give quick answers without really checking their own thinking, which can lead to mistakes, especially on complex questions that need careful reasoning. This limits how well these models can perform on challenging tasks that require more than just a fast guess.
What's the solution?
The researchers improved these models by adding reinforcement learning, which rewards the AI for thinking things through and double-checking its answers. The Forced Rethinking technique makes the model pause and reconsider its response, leading to more accurate and thoughtful answers. With these changes, the models reached top scores on math and science tests and started to act more like systems that take their time to think deeply.
Why it matters?
This work matters because it helps AI become more reliable and trustworthy, especially for subjects where getting the right answer really matters. By encouraging the models to reflect and reason more carefully, VL-Rethinker brings us closer to having AI that can solve complex problems just like a thoughtful human would.
Abstract
Vision-language models enhanced with reinforcement learning and Forced Rethinking achieve state-of-the-art performance on math and science benchmarks and approach the capabilities of slow-thinking systems.