VMoBA: Mixture-of-Block Attention for Video Diffusion Models
Jianzong Wu, Liang Hou, Haotian Yang, Xin Tao, Ye Tian, Pengfei Wan, Di Zhang, Yunhai Tong
2025-07-01
Summary
This paper talks about VMoBA, a new technique that improves video diffusion models by using a special attention method called Mixture-of-Block Attention to make generating long and high-quality videos faster and better.
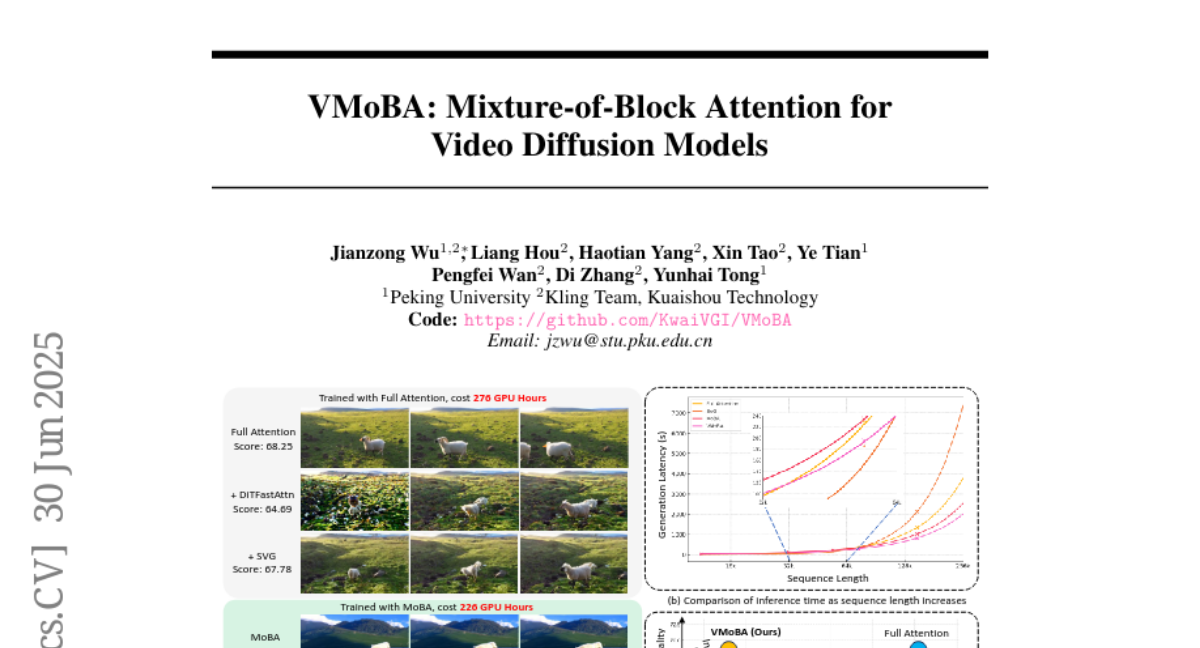
What's the problem?
Video diffusion models need to handle a huge amount of data because videos have many frames and are high-resolution, which makes them slow and expensive to run while sometimes not producing the best quality.
What's the solution?
VMoBA introduces a sparse attention system that focuses processing power on important blocks of the video data instead of everything at once. This reduces the amount of work the model has to do, speeding up the video generation while keeping or improving the video quality.
Why it matters?
This matters because it advances the ability of AI to create longer, clearer videos more efficiently, which can help in creative industries, video editing, and AI-generated content production.
Abstract
VMoBA, a novel sparse attention mechanism, enhances Video Diffusion Models by improving efficiency and quality in generating long-duration, high-resolution videos.