VOCABTRIM: Vocabulary Pruning for Efficient Speculative Decoding in LLMs
Raghavv Goel, Sudhanshu Agrawal, Mukul Gagrani, Junyoung Park, Yifan Zao, He Zhang, Tian Liu, Yiping Yang, Xin Yuan, Jiuyan Lu, Chris Lott, Mingu Lee
2025-07-01
Summary
This paper talks about VocabTrim, a new method that makes language models generate text faster by shrinking the number of words or tokens they think about during certain parts of the text creation process.
What's the problem?
The problem is that when language models generate text, especially big ones, they spend a lot of time considering a huge vocabulary, which slows down the process and uses up a lot of computer memory.
What's the solution?
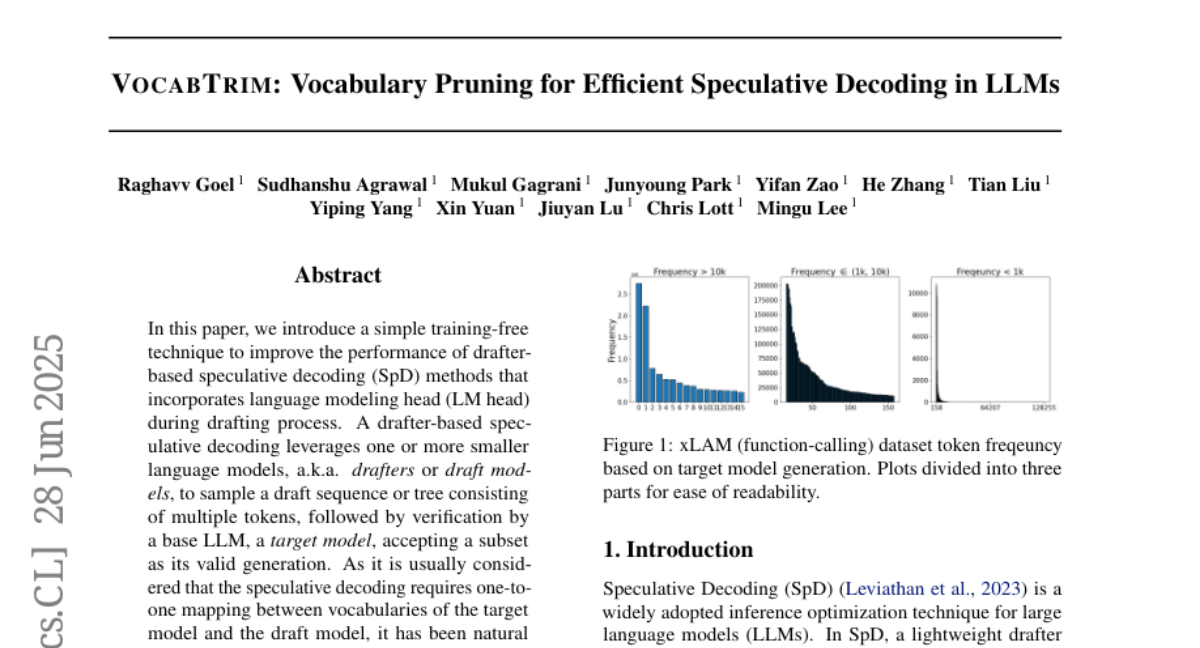
The researchers created VocabTrim, which cuts down the vocabulary size by only keeping the most commonly used tokens during the drafting phase of text generation. This way, the model can work faster and use less memory without losing much accuracy.
Why it matters?
This matters because faster language models save time and computing resources, which is especially important for devices with limited memory, making advanced language technology more accessible and efficient.
Abstract
A technique called VocabTrim improves the generation speed of drafter-based speculative decoding by reducing the vocabulary size of the drafter LM head, leading to higher memory-bound speed-up.