Zero-Shot Vision Encoder Grafting via LLM Surrogates
Kaiyu Yue, Vasu Singla, Menglin Jia, John Kirchenbauer, Rifaa Qadri, Zikui Cai, Abhinav Bhatele, Furong Huang, Tom Goldstein
2025-05-29
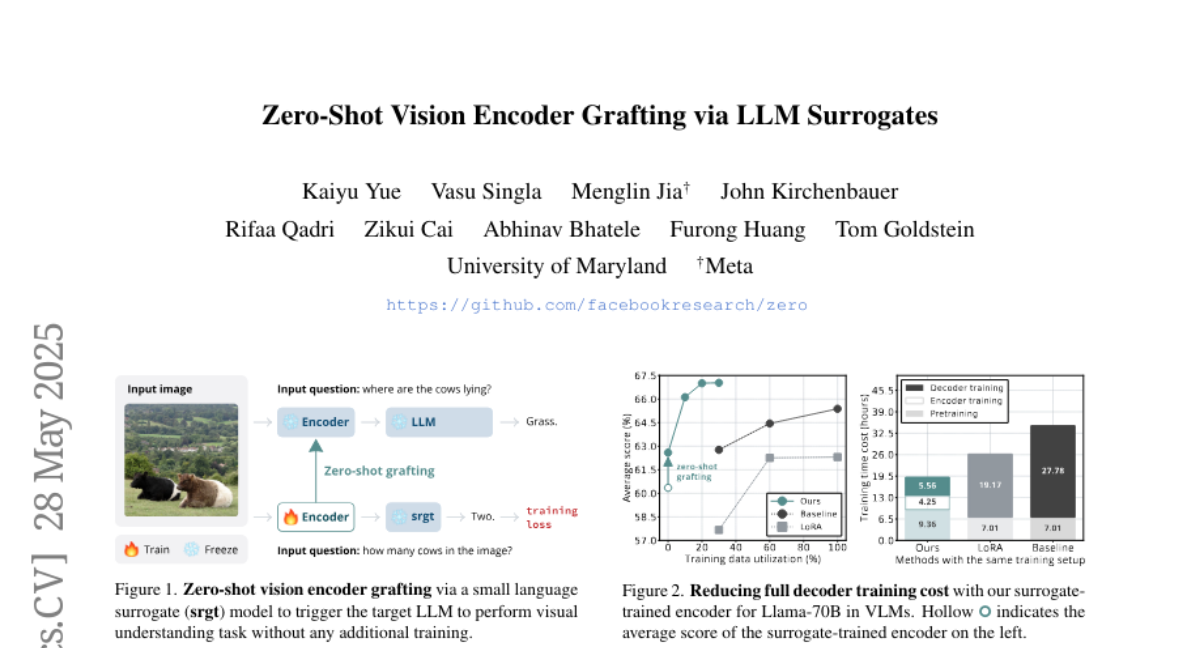
Summary
This paper talks about a new way to train computer models that can understand images, making the process cheaper and more effective by using smaller helper models before connecting the image understanding to a bigger language model.
What's the problem?
The problem is that teaching large AI models to understand both images and text usually takes a lot of time, money, and computer power. Training everything together from scratch is expensive and not very efficient.
What's the solution?
The researchers came up with a method where they first train smaller, simpler models to handle the image understanding part. Once these smaller models are good at their job, their knowledge is transferred to the larger language model. This makes the whole process faster and less costly, while still getting great results.
Why it matters?
This is important because it makes advanced AI technology more accessible and affordable, allowing more people and companies to use powerful models that can understand both pictures and words. It also helps speed up progress in areas like search engines, digital assistants, and smart devices.
Abstract
The approach of training vision encoders with small surrogate models before transferring them to large language models reduces training costs and enhances performance.